機械学習 およびデータマイニング 理論
偏りと分散 のトレードオフ計算論的学習理論(英語版) 経験損失最小化(英語版) オッカム学習(英語版) PAC学習 統計的学習(英語版) VC理論(英語版) 学会・論文誌等
NIPS(英語版) ICML(英語版) ML(英語版) JMLR(英語版) ArXiv:cs.LG
サポートベクターマシン (英 : support-vector machine , SVM )は、教師あり学習 を用いるパターン認識 モデルの1つである。分類や回帰 へ適用できる。1963年 にウラジミール・ヴァプニク(英語版) とAlexey Ya. Chervonenkisが線形サポートベクターマシンを発表し[1] 1992年 にBernhard E. Boser、Isabelle M. Guyon、ウラジミール・ヴァプニクが非線形へと拡張した。
サポートベクターマシンは、現在知られている手法の中でも認識性能が優れた学習 モデルの1つである。サポートベクターマシンが優れた認識性能を発揮することができる理由は、未学習データに対して高い識別性能を得るための工夫があるためである。
基本的な考え方 サポートベクターマシンは、線形入力素子を利用して2クラスのパターン 識別器を構成する手法である。訓練サンプルから、各データ点との距離が最大となるマージン最大化超平面を求めるという基準(超平面分離定理 )で線形入力素子のパラメータを学習 する。
最も簡単な場合である、与えられたデータを線形に分離することが可能 な(例えば、3次元のデータを2次元平面で完全に区切ることができる)場合を考えよう。
このとき、SVMは与えられた学習用サンプルを、もっとも大胆に区切る境目を学習する。学習の結果得られた超平面は、境界に最も近いサンプルとの距離(マージン )が最大となるパーセプトロン (マージン識別器 )で定義される。すなわち、そのようなパーセプトロンの重みベクトル w ∈ R p {\displaystyle {\boldsymbol {w}}\in \mathbb {R} ^{p}} { x ∈ R p ∣ x ⋅ w = 0 } {\displaystyle \{{\boldsymbol {x}}\in \mathbb {R} ^{p}\mid {\boldsymbol {x}}\cdot {\boldsymbol {w}}=0\}}
学習過程はラグランジュの未定乗数法 とKKT条件 を用いることにより、最適化問題 の一種である凸二次計画 問題で定式化される。ただし、学習サンプル数が増えると急速に計算量が増大するため、分割統治法 の考え方を用いた手法なども提案されている。
概念的特長 次のような学習データ集合 D {\displaystyle {\mathcal {D}}}
D = { ( x i , y i ) ∣ x i ∈ R p , y i ∈ { − 1 , 1 } } i = 1 n {\displaystyle {\mathcal {D}}=\{({\boldsymbol {x}}_{i},y_{i})\mid {\boldsymbol {x}}_{i}\in \mathbb {R} ^{p},\,y_{i}\in \{-1,1\}\}_{i=1}^{n}} y i {\displaystyle y_{i}} x i {\displaystyle {\boldsymbol {x}}_{i}} x i {\displaystyle {\boldsymbol {x}}_{i}} p {\displaystyle p}
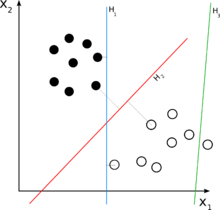
H3は2つのクラスのいくつかの点を正しく分類していない。H1とH2は2つのクラスのいくつかの点を分類するのに、H2がH1よりもっと大きいマージンを持って分類することを確認することができる。 ニューラルネットワーク を含む多くの学習アルゴリズムは、このような学習データが与えられた時 y i = 1 {\displaystyle y_{i}=1} y i = − 1 {\displaystyle y_{i}=-1}
線形 SVM 2クラスのサンプルで学習したSVMの最大マージン超平面とマージン。マージン上のサンプルはサポートベクターと呼ばれる。 以下のような形式の n {\displaystyle n}
( x 1 , y 1 ) , … , ( x n , y n ) , {\displaystyle ({\boldsymbol {x}}_{1},y_{1}),\ldots ,({\boldsymbol {x}}_{n},y_{n}),} y i {\displaystyle y_{i}} x i {\displaystyle {\boldsymbol {x}}_{i}} x i {\displaystyle {\boldsymbol {x}}_{i}} p {\displaystyle p} y i = 1 {\displaystyle y_{i}=1} x i {\displaystyle {\boldsymbol {x}}_{i}} y i = − 1 {\displaystyle y_{i}=-1} x i {\displaystyle {\boldsymbol {x}}_{i}} x i {\displaystyle {\boldsymbol {x}}_{i}}
超平面は下記を満たす点 x {\displaystyle {\boldsymbol {x}}}
w T x − b = 0 , {\displaystyle {\boldsymbol {w}}^{T}{\boldsymbol {x}}-b=0,} ここで、 w {\displaystyle {\boldsymbol {w}}} w {\displaystyle {\boldsymbol {w}}} b / ‖ w ‖ {\displaystyle b/\|{\boldsymbol {w}}\|}
ハードマージン 学習データが線形分離可能 であるとき、なるべくその距離が大きくなるように、2つのクラスのデータを分離するような、2つの平行な超平面を選択することができる。2つの超平面の間はマージン、2つの超平面の中間に位置する超平面は最大マージン超平面と呼ばれる。
正規化ないし標準化されたデータセットでは、これらの超平面は次の式で表される。
w T x − b = 1 {\displaystyle {\boldsymbol {w}}^{T}{\boldsymbol {x}}-b=1} と
w T x − b = − 1 {\displaystyle {\boldsymbol {w}}^{T}{\boldsymbol {x}}-b=-1} この2つの超平面の間の距離は、幾何学的には、点と平面の距離(英語版) の公式を用いて、 2 / ‖ w ‖ {\displaystyle 2/\|{\boldsymbol {w}}\|} [2] ‖ w ‖ {\displaystyle \|{\boldsymbol {w}}\|}
点がマージンに入らず、正しい側にいるための制約条件は、全ての i {\displaystyle i}
{ w T x i − b ≥ 1 if y i = 1 w T x i − b ≤ − 1 if y i = − 1 {\displaystyle {\begin{cases}{\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b\geq 1&{\text{if}}\quad y_{i}=1\\{\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b\leq -1&{\text{if}}\quad y_{i}=-1\end{cases}}} つまり、全て i {\displaystyle i}
y i ( w T x i − b ) ≥ 1 ⋯ ⋯ ( 1 ) {\displaystyle y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\geq 1\qquad \cdots \cdots \,(1)} 以上をまとめると、次の最適化問題が得られる。
"Minimize ‖ w ‖ {\displaystyle \|{\boldsymbol {w}}\|} y i ( w T x i − b ) ≥ 1 {\displaystyle y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\geq 1} i = 1 , … , n {\displaystyle i=1,\ldots ,n} これを解いて得られる w {\displaystyle {\boldsymbol {w}}} b {\displaystyle b} x ↦ sgn ( w T x − b ) {\displaystyle {\boldsymbol {x}}\mapsto \operatorname {sgn}({\boldsymbol {w}}^{T}{\boldsymbol {x}}-b)} sgn ( ⋅ ) {\displaystyle \operatorname {sgn}(\cdot )} 符号関数 である。
この幾何学的記述から、最大マージン超平面は、それと最も近い位置にある x i {\displaystyle {\boldsymbol {x}}_{i}} x i {\displaystyle {\boldsymbol {x}}_{i}}
ソフトマージン SVMを拡張して線形分離可能ではないデータを扱えるようにするためには、ヒンジ損失(英語版) 関数が有用である。
max ( 0 , 1 − y i ( w T x i − b ) ) . {\displaystyle \max \left(0,1-y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\right).} ここで、 y i {\displaystyle y_{i}} i {\displaystyle i} w T x i − b {\displaystyle {\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b} i {\displaystyle i}
この関数の値は、(1) の制約が満たされている場合、つまり、 x i {\displaystyle {\boldsymbol {x}}_{i}}
最適化の目的は、以下を最小化することである。
[ 1 n ∑ i = 1 n max ( 0 , 1 − y i ( w T x i − b ) ) ] + λ ‖ w ‖ 2 , {\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\right)\right]+\lambda \lVert {\boldsymbol {w}}\rVert ^{2},} パラメータ λ {\displaystyle \lambda } x i {\displaystyle {\boldsymbol {x}}_{i}} λ {\displaystyle \lambda }
線形分離不可能な問題への適用 1963年にウラジミール・ヴァプニク(英語版) 、Alexey Ya. Chervonenkis が発表した初期のサポートベクターマシンは、線形分類器 にしか適用できなかった。しかし、再生核ヒルベルト空間 の理論を取り入れたカーネル関数 (英語版) 特徴空間(英語版) へ写像し、特徴空間上で線形分離を行う手法が 1992年にBernhard E. Boser、Isabelle M. Guyon、ウラジミール・ヴァプニク(英語版) らによって提案された。これにより、非線形 分類問題にも優れた性能を発揮することがわかり、近年特に注目を集めている。
なお、カーネル関数を取り入れた一連の手法では、どのような写像 が行われるか知らずに計算できることから、カーネルトリック (Kernel Trick) と呼ばれている。
主に下記のカーネル関数がよく使われていてLIBSVMでも実装されている。
SVM分類器の計算 ソフトマージンSVM分類器の計算は、次のような式を最小化することになる
[ 1 n ∑ i = 1 n max ( 0 , 1 − y i ( w T x i − b ) ) ] + λ ‖ w ‖ 2 ⋯ ⋯ ( 2 ) {\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\right)\right]+\lambda \|{\boldsymbol {w}}\|^{2}\qquad \cdots \cdots \,(2)} 線形分離可能な入力データに対して、 λ {\displaystyle \lambda } 二次計画法 問題に帰着するものである。
主形式 (2) の最小化問題は、微分可能な目的関数を持つ制約付き最適化問題に書き換えることができる。
i ∈ { 1 , … , n } {\displaystyle i\in \{1,\,\ldots ,\,n\}} ζ i = max ( 0 , 1 − y i ( w T x i − b ) ) {\displaystyle \zeta _{i}=\max \left(0,1-y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\right)} ζ i {\displaystyle \zeta _{i}} y i ( w T x i − b ) ≥ 1 − ζ i {\displaystyle y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\geq 1-\zeta _{i}}
したがって、最適化問題を次のように書き換えることができる。
minimize 1 n ∑ i = 1 n ζ i + λ ‖ w ‖ 2 {\displaystyle {\text{minimize }}{\frac {1}{n}}\sum _{i=1}^{n}\zeta _{i}+\lambda \|{\boldsymbol {w}}\|^{2}} subject to y i ( w T x i − b ) ≥ 1 − ζ i and ζ i ≥ 0 , for all i . {\displaystyle {\text{subject to }}y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\geq 1-\zeta _{i}\,{\text{ and }}\,\zeta _{i}\geq 0,\,{\text{for all }}i.} 双対形式 次のような双対形式に帰着することができる。
maximize f ( c 1 … c n ) = ∑ i = 1 n c i − 1 2 ∑ i = 1 n ∑ j = 1 n y i c i ( x i T x j ) y j c j , {\displaystyle {\text{maximize}}\,\,f(c_{1}\ldots c_{n})=\sum _{i=1}^{n}c_{i}-{\frac {1}{2}}\sum _{i=1}^{n}\sum _{j=1}^{n}y_{i}c_{i}({\boldsymbol {x}}_{i}^{T}{\boldsymbol {x}}_{j})y_{j}c_{j},} subject to ∑ i = 1 n c i y i = 0 , and 0 ≤ c i ≤ 1 2 n λ for all i . {\displaystyle {\text{subject to }}\sum _{i=1}^{n}c_{i}y_{i}=0,\,{\text{and }}0\leq c_{i}\leq {\frac {1}{2n\lambda }}\;{\text{for all }}i.} 双対形式の最大化問題は、線形制約を前提とした c i {\displaystyle c_{i}} 二次計画法 のアルゴリズムで効率的に解くことができる。
ここで、 c i {\displaystyle c_{i}}
w = ∑ i = 1 n c i y i x i {\displaystyle {\boldsymbol {w}}=\sum _{i=1}^{n}c_{i}y_{i}{\boldsymbol {x}}_{i}} さらに、 x i {\displaystyle {\boldsymbol {x}}_{i}} c i = 0 {\displaystyle c_{i}=0} x i {\displaystyle {\boldsymbol {x}}_{i}} 0 < c i < ( 2 n λ ) − 1 {\displaystyle 0<c_{i}<(2n\lambda )^{-1}} w {\displaystyle {\boldsymbol {w}}}
オフセット b {\displaystyle b} x i {\displaystyle {\boldsymbol {x}}_{i}}
y i ( w T x i − b ) = 1 ⟺ b = w T x i − y i . {\displaystyle y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)=1\iff b={\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-y_{i}.} ここで、 y i = ± 1 {\displaystyle y_{i}=\pm 1} y i − 1 = y i {\displaystyle y_{i}^{-1}=y_{i}}
構造化SVM 2005年 にIoannis Tsochantaridisらが構造化SVM(英語版) を発表した[3]
通常の二値分類SVMは以下の値で分類する。
y ^ ( x ; w ) = sign ⟨ w , x ⟩ {\displaystyle {\hat {y}}(x;w)={\text{sign}}\langle w,x\rangle } これは、このようにも書ける。
y ^ ( x ; w ) = a r g m a x y ∈ { − 1 , 1 } ⟨ w , y x ⟩ {\displaystyle {\hat {y}}(x;w)={\underset {y\in \{-1,1\}}{\operatorname {arg\,max} }}\ \langle w,yx\rangle } その上で、これを二値から一般の値に拡張する。 Ψ {\displaystyle \Psi }
y ^ ( x ; w ) = a r g m a x y ∈ Y ⟨ w , Ψ ( x , y ) ⟩ {\displaystyle {\hat {y}}(x;w)={\underset {y\in {\mathcal {Y}}}{\operatorname {arg\,max} }}\ \langle w,\Psi (x,y)\rangle } そして、下記の損失関数を最小化するように、最適化問題 を解く。ここではL2正則化 を付けている。 C {\displaystyle C} Δ {\displaystyle \Delta } Δ ( y , y ) = 0 {\displaystyle \Delta (y,y)=0}
E ( w ) = ‖ w ‖ 2 + C ∑ i = 1 n Δ ( y i , y ^ ( x i ; w ) ) {\displaystyle E(w)=\|w\|^{2}+C\sum _{i=1}^{n}\Delta (y_{i},{\hat {y}}(x_{i};w))} 上記の最適化問題を解くには工夫が必要であり、その後も提案が続いているが、2005年に提案された方法は下記のように上界となる関数 L i ( w ) {\displaystyle L_{i}(w)}
Δ ( y i , y ^ ( x i ; w ) ) ≤ L i ( w ) {\displaystyle \Delta (y_{i},{\hat {y}}(x_{i};w))\leq L_{i}(w)} その上で、下記の最適化問題を解く。
E ( w ) = ‖ w ‖ 2 + C ∑ i = 1 n L i ( w ) {\displaystyle E(w)=\|w\|^{2}+C\sum _{i=1}^{n}L_{i}(w)} L i ( w ) {\displaystyle L_{i}(w)}
マージンリスケーリング L i ( w ) = sup y ∈ Y Δ ( y i , y ) + ⟨ w , Ψ ( x i , y ) ⟩ − ⟨ w , Ψ ( x i , y i ) ⟩ {\displaystyle L_{i}(w)=\sup _{y\in {\mathcal {Y}}}\Delta (y_{i},y)+\langle w,\Psi (x_{i},y)\rangle -\langle w,\Psi (x_{i},y_{i})\rangle } スラックリスケーリング L i ( w ) = sup y ∈ Y Δ ( y i , y ) ( 1 + ⟨ w , Ψ ( x i , y ) ⟩ − ⟨ w , Ψ ( x i , y i ) ⟩ ) {\displaystyle L_{i}(w)=\sup _{y\in {\mathcal {Y}}}\Delta (y_{i},y)\left(1+\langle w,\Psi (x_{i},y)\rangle -\langle w,\Psi (x_{i},y_{i})\rangle \right)} 参照 ^ V. Vapnik and A. Lerner. Pattern recognition using generalized portrait method. Automation and Remote Control, 24, 1963. ^ “Why is the SVM margin equal to 2 ‖ w ‖ {\displaystyle {\frac {2}{\|{\boldsymbol {w}}\|}}} ”. Mathematics Stack Exchange . 20150530 閲覧。 ^ Ioannis Tsochantaridis; Thorsten Joachims; Thomas Hofmann; Yasemin Altun (2005). “Large Margin Methods for Structured and Interdependent Output Variables”. The Journal of Machine Learning Research 6 (9): 1453-1484. http://www.jmlr.org/papers/volume6/tsochantaridis05a/tsochantaridis05a.pdf . 関連項目 この項目は、工学 ・技術 に関連した書きかけの項目 です。この項目を加筆・訂正などしてくださる協力者を求めています(Portal:技術と産業)。
典拠管理データベース: 国立図書館 フランス BnF data ドイツ イスラエル アメリカ チェコ































![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\right)\right]+\lambda \lVert {\boldsymbol {w}}\rVert ^{2},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c87b945eac2fcf0d1d282c58885a6761114e127)

![{\displaystyle \left[{\frac {1}{n}}\sum _{i=1}^{n}\max \left(0,1-y_{i}({\boldsymbol {w}}^{T}{\boldsymbol {x}}_{i}-b)\right)\right]+\lambda \|{\boldsymbol {w}}\|^{2}\qquad \cdots \cdots \,(2)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a82b368311f1c098552db3617829f42a846568a0)


































